自己紹介
今年の夏、Microsoftインターンの福川遥です。アメリカで生まれ、フィリピンで育ちました。今はニューヨークの大学、New York Universityで数学を勉強している4年生です。一昨年休学をして日本語を勉強するために初めて日本に住んでみました。それから日本での生活が気に入り、将来は東京で働きたいと思うようになりました。去年からプログラミングを始め、様々なインターンシップをやっている 内にテクノロジーを触る仕事に就きたいと決めました。まだプログラミングも日本語も勉強中ですが、Microsoftのインターンシップ一ヶ月の期間でやったプロジェクトを皆さまに披露させていただきます。
Azure Batchで並列計算
プロジェクトの一環とし、何千個かのWikipediaの特定のアメリカ人の人種に関わる記事に一番多く使われている言葉をAzure batchで数えてみました。結果が出た後、Azure Batch でノード数によってどのくらい計算のスピードが変わるか気になり始めました。しかし、私が使っていた目的だと計算の時間がノード数だけに影響されるだけでは無く、 記事の長さによってかなり計算時間に差が出てしまうことに気づきました。よって、この手法だと Azure Batch 単体のパフォーマンス分析には不向きだと思い、数学を用いてノード数と計算速度の関係を調べるというアプローチに変更しました。
ノード数の影響を観察直接するために、Azure Batchで数値積分をするプログラムを書いてノード数を変えながら時間を計ってみました。
バイアスのないテストをするために、定積分 をリーマン和で計算させるプログラムを作りました。まず区間、x ∈[0,100π] 、を一億個の等しい子区間に分けてそれを100個のタスクに入れてAzure batchに送り、リーマン和を計算しました 。 全部の子区間を同じメッシュサイズにすることで問題だった記事の長さの誤差等の問題に影響されずノード数だけに影響される計算のスピードが測れました。実験の結果、ノード数(x)を変えると時間(t)はこのように変わることが判明しました。

(この数式ではtが計算にかかった時間、xがノードの数、cはコンスタントです)つまり、ノード数を増やすと計算時間は短くなりますが、ノード数を増やすにつれ、計算時間から削れる時間はどんどん減ってしまいます。すなわち、計算時間を半分にするには使っているノード数の4倍のノード数を使わないとならないということです。
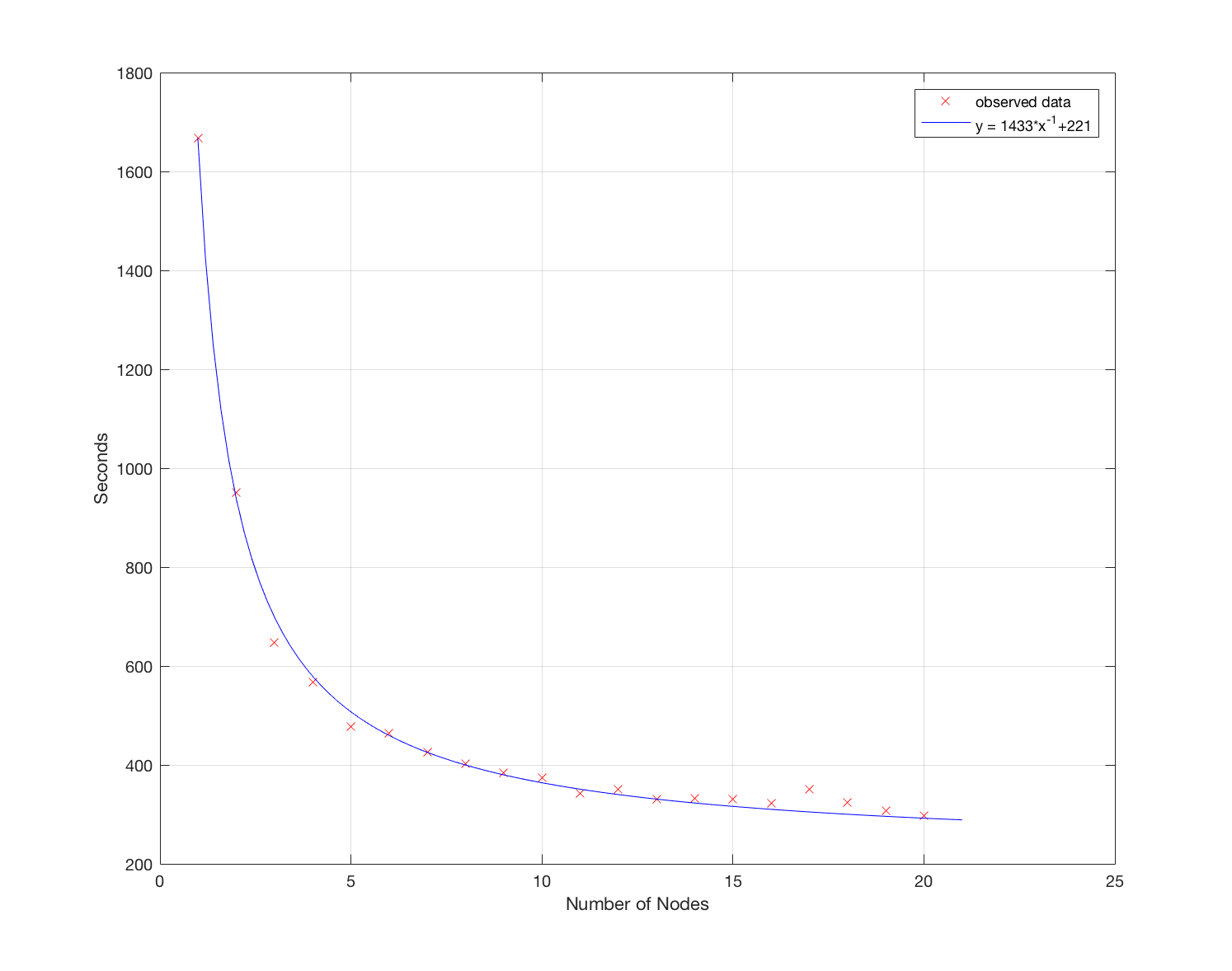
グラフから見える通り、この数式は結構明確な的確な関連性を表してます。c=1271.4はプログラムの内容によるので、気にしなくていいです。
ノード数17 のケースを例に挙げると、ある程度のノード数を超えると、合計計算時間が長くなるケースもありました。これは Azure Batch で仮想マシン (ノード) を準備する時間にも依存するという推測をしています。
なお、Azure batchの制限により、このスピードの数式はノード数20個までしか使えません。。特別に申請しない限りノード数20個までしか使うことができません。よって、20個以上のノードをプログラム上で使おうとしても、結果として20個しか使われません。
Azure Batchプロジェクト
まずAzure Batch でサンプルの Python コードを使えるようにします。
- Azureポータルから[新規]→ [Batch サービス]をクリックします。

- [作成]をクリックします。
ここで、必要な欄に情報を入力します。全て同じデータセンターの場所を選んだ方が通信スピードが速いので、ここでは例として全て東日本を選択します。
- このチュートリアルを見ながら処理を進めてください。ここでは pythonを例として使うため、pythonのコードとチュートリアルを閲覧して進めています。PythonのコードはAnaconda Spyderを使って記述しています。
- サンプルコードをダウンロードし、 “python_tutorial_client.py” とを開きます。
“python_tutorial_client.py”はローカルクライアント側で動かすクライアントコードです。“python_tutorial_task.py”はサーバー側(Azure Batch側)で動かすタスクコードです。以下ではそれぞれ“タスクコード”、“クライアントコード”として話します。
- タスクコード:python_tutorial_task.py
- クライアントコード:python_tutorial_client.py
コードを実行させるにはClientのコードをこのように書き換えます:
- “target_dedicated” を “target_dedicated_nodes”に書き換えます。
- Azure Batchの認証情報 (“_BATCH_ACCOUNT_NAME” と“_STORAGE_ACCOUNT_KEY”) に対して適切な設定をします。
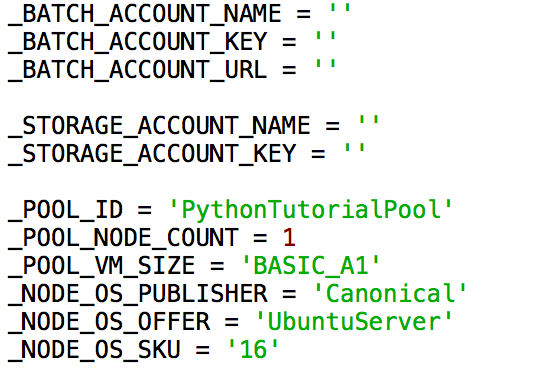
Azure Batch の認証情報のアカウント名, キー , URL はAzure Batchポータルの[キー]に載っています。
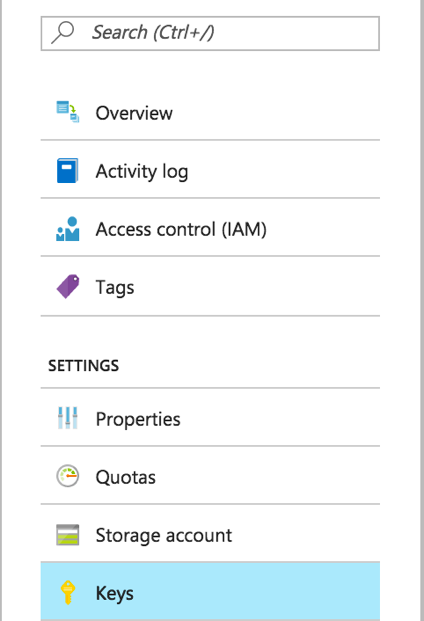
ストレージアカウント名とキーは[ストレージアカウント]にあります。
Azure Batchアカウントもストレージアカウントもキーが 2 つ載っていますが1つ目のキーしか使用しません。
- python_tutorial_client.pyのプログラムを Python から実行してください。ちなみに筆者はMac使っていたので、プログラムを動かすためにはTerminalからPython3 python_tutorial_client.pyで動かしました。Windowsコマンドプロンプトでも似たようなコマンドがあります。
- もし成功したら、AzureポータルのBatchの[概要]画面のグラフに変化があるはずです。そして、使っているコンピューターに “taskdata1_OUTPUT.txt” 等とファイルがダウンロードできるようになります。
ここまでで、Azure Batch上でプログラムが使えるようになりました。このチュートリアルのプログラムはtaskdataの中に頻繁に使われている3つの言葉を探して、そしてその言葉が何回使われているかをアウトプットします。
Python のサンプルコードを独自のものに改編します
今回、サンプルプロジェクトの一環として、人種ごとの、アメリカ人に関連したWikipediaの記事を何千個かインプットし、一番多く使われている40個の語彙とその語彙がどれだけ頻繁に現れるかをアウトプットする、というプログラムをAzure Batchで走らせてみましした。(これは、筆者がどういう単語が多く出てくるかを興味を持ったためです。)
まずアメリカの黒人に関する記事から始めたのでBlack Americansの例を使って進みます。他の人種の記事の扱いも同じようにしました。
- まずPythonでWikipediaに載っている記事のリストから記事をダウンロードするプログラムを追加します。
- 先ほど使っていたチュートリアルのクライアントコードのインプットをファイルのリストではなくフォルダーからリストアップするように変えます。
例えばアメリカの黒人に関する記事を2277ファイルダウンロードしたので 全てリストとして書くのは大変なので、インプットをフォルダーに替えたほうが楽でした。
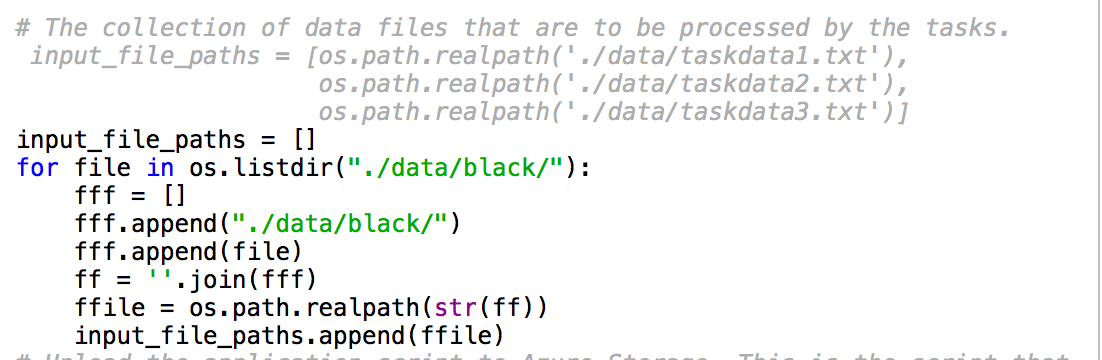
- Azure Batchでは一つのジョブに100個のタスクしか入れることができません。記事毎ののタスクにしたかったので、クライアントコードを少し換える必要があります。インプットファイルを100個ずつのチャンクにし、ジョブを必要な数まで増やします。
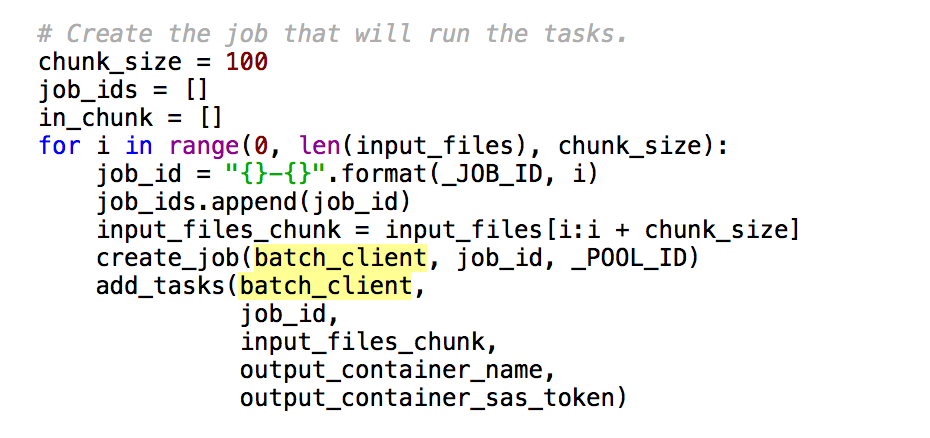
- 元のコードだと一番多い3個の語彙しかアウトプットされなかったので、それを一つの記事に60個までアウトプットするように変更。
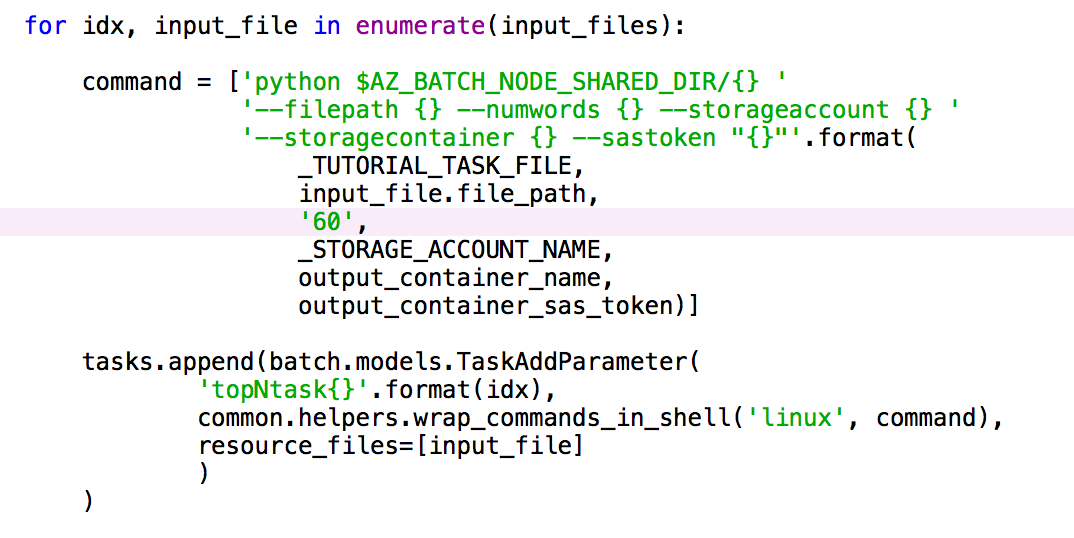
- 後で集計カウンターを作る時にアウトプットを扱いやすくするために、アウトプットファイルに書かれる情報の形式をタスクコードで変更。
そして、Job ID や node name等使われない情報を出力対象から消します。
- クライアント コードをコマンドラインでPython3から実行します。
- アウトプットされたファイルをblackOUTPUTというフォルダーに入れます。
- 次はアウトプットされたカウントを集計カウントにまとめました。トップ40の語彙をまとめることにしました。
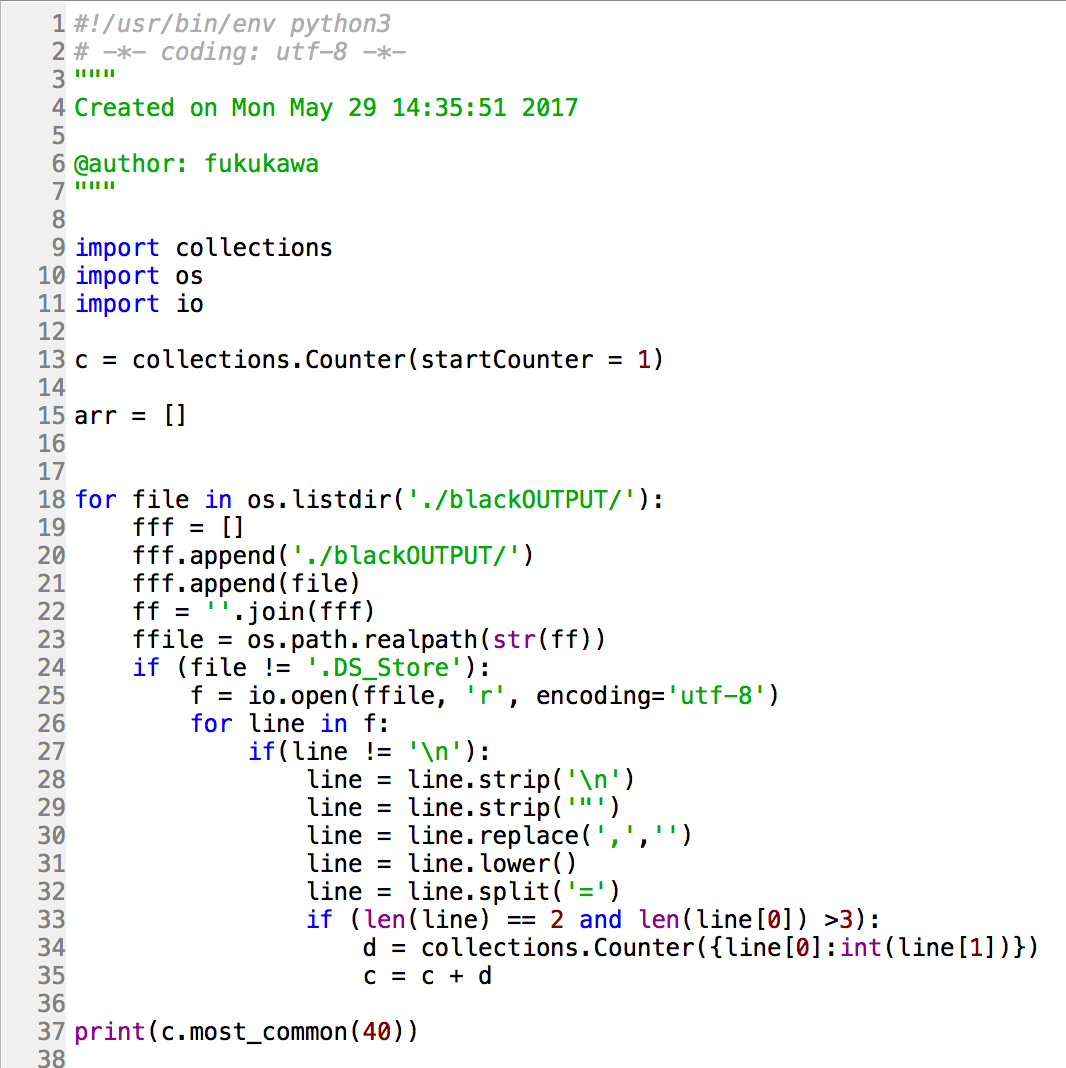
ここまでで、黒人に関する人種の記事の処理は終了です。この後、他の人種についても同じ処理を実施します。
ノードの増加と処理のスピードの変化率
このプロセスを他のアメリカにいる人種の記事にも実施していたのですが、実はここで、Azure Batchの処理時間で気になる点がありました。実際に発生した現象は、ノードの数を増加しても、意図通り計算スピードが上がらず、処理時間がかかる事象が発生したのです。問題をまとめると以下のような状態です。
問題
ノードの数を増加させても、計算スピードが上がらず、処理時間が改善せず一定になる。
もともと想定していた速度としては以下のように処理時間が低減すると思っていました。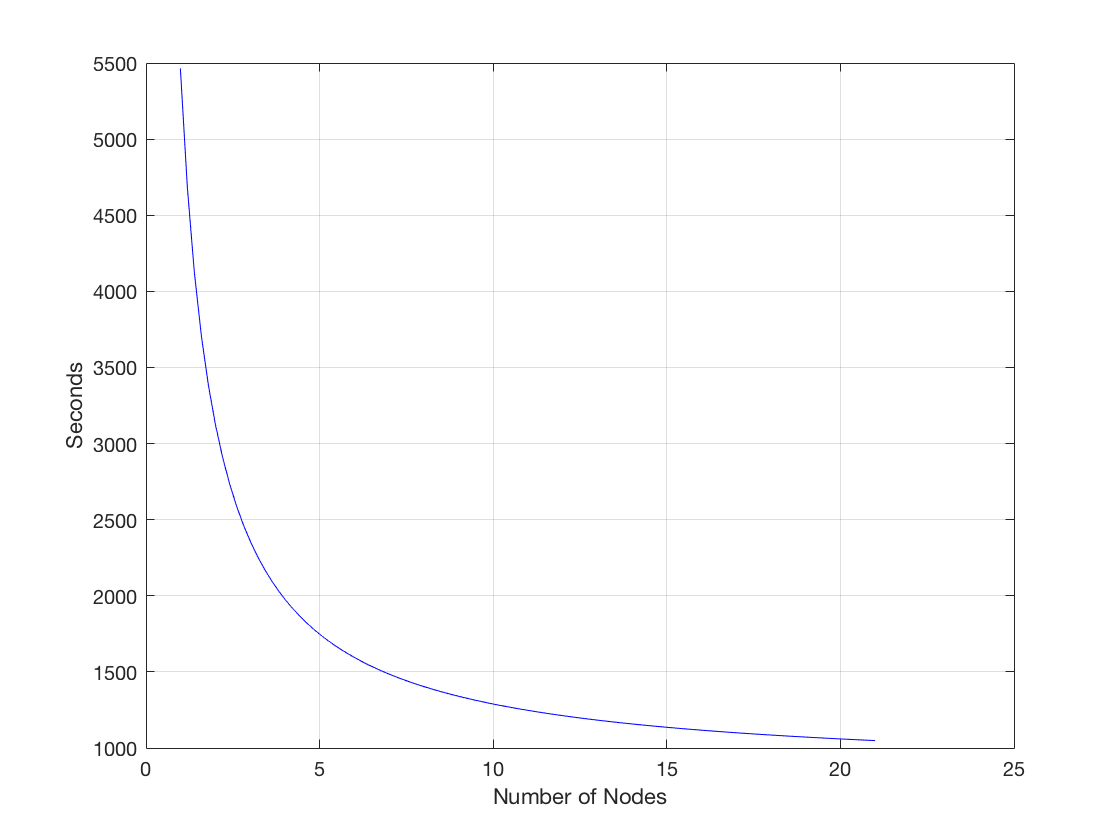
しかし現実はこうでした。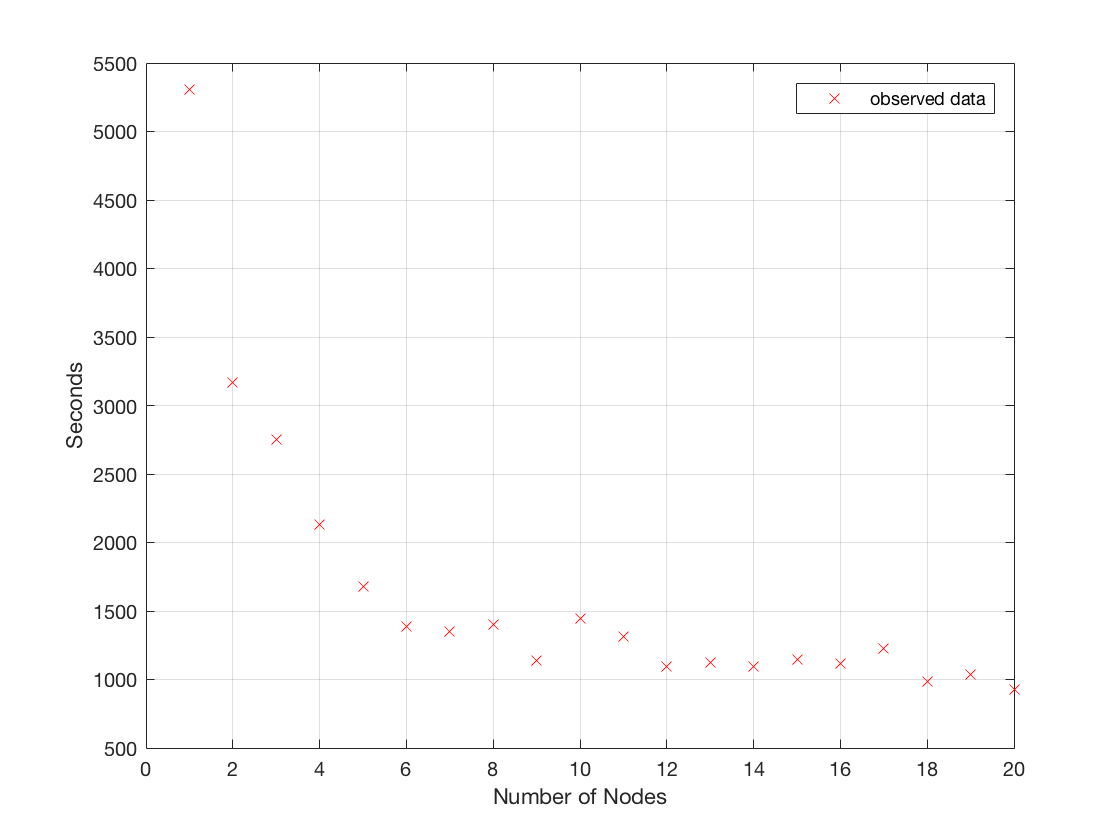
まずは “_POOL_NODE_COUNT” をクライアントコードで換えながら処理時間を計っていましたが、記事の長さが全てバラバラだったのでノード数を換えてもあまり公平に時間が測れない状態でした。
ジョブ毎の時間を計ってみると、一つ一つのジョブの処理スピードがバラバラだと気付きました。しかも、ジョブの中のタスク毎の処理スピードも計ってみると、ファイルの大きさによって処理スピードに誤差が出てることに気づきました。このため、ノード数を増やすとスピードが上がることが多かったが、スピードの変化率を予想することは難しかったです。
例えば、処理に1分掛かるファイル、2分掛かるファイル、3分掛かるファイル、とファイルが3つあります。1つのノードで処理するなら、6分かかります。2つのノードなら3分掛かります。しかし、もしノードを3つに増やしても、1つのファイルは1つのノードにしか処理されないため、3分かかります。
一片で処理するタスクの数を増やしても、一つのタスクは一つのノードで処理されるため、処理時間の変化に直接影響が表れなかったです。そのため、長さがバラバラの記事を処理させるプログラムはノード数と処理時間の関係を調べるには不向きだと考えました。
この問題はビンパッキング問題の一種で、NP‐completeです。
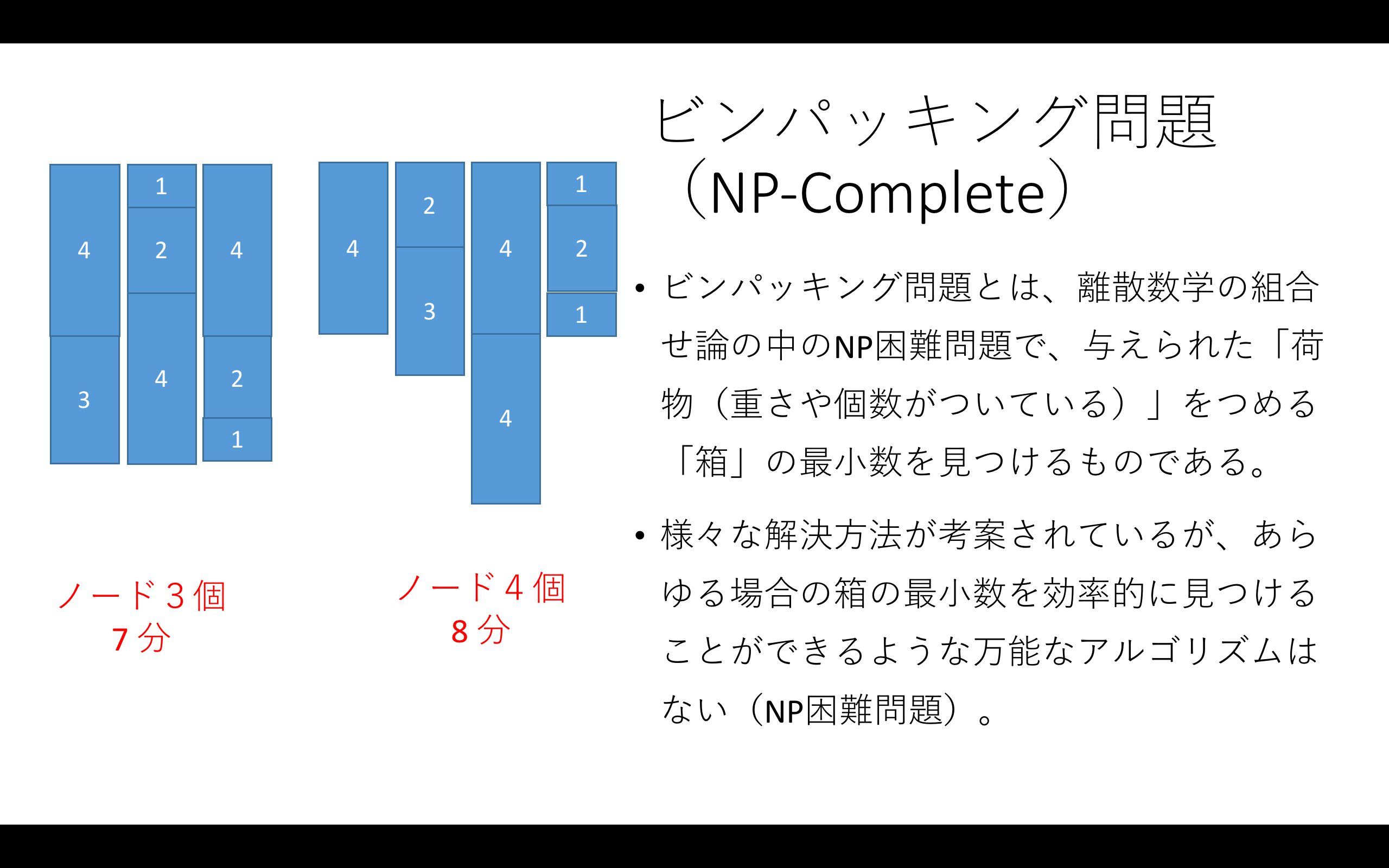
ノード数によっての計算のスピードを一貫性のある方法で測りたかったので、Azure Batchとノードの関係を調べるために、数学の「定積分の問題」を大きさの統一されたメッシュサイズを使っての数値積法の一種であるリーマン和(区分求積分)で計算するプログラムを書いて測ることにしました。
Azure Batchを使ってリーマン和の計算
まず、クライアントコードで区間を一億の小区間に分けて、その小区間を100個のインプットファイルに分けます。タスクコードから計算される部分和を保存するAzure テーブルもクライアントコードで作成します。
タスクコードではインプットファイルから読み取る小区間のリーマン和を計算し、Azure Tableに入れます。
全てのタスク完了後、クライアントコードがAzure Tableに記録した部分和を全て足して定積分のリーマン和を標準出力(STDOUT)でプリントするプログラムを作りました。実際に実用したのは以下の通りです。
- クライアントコードの最初に _TABLE, num_points, x_max, と numsize を追加します。
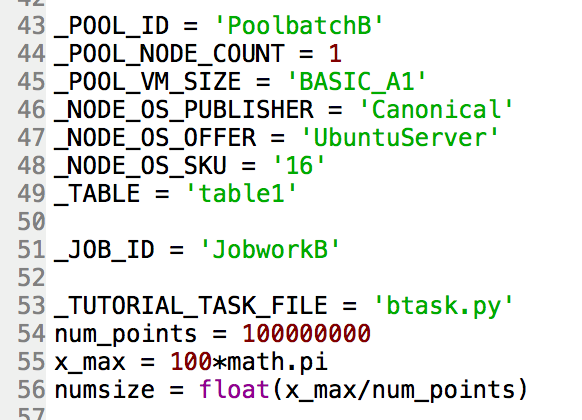
- クライアントコードのadd_tasks 関数の中の numwords 引数をstr(numsize)に変更します。
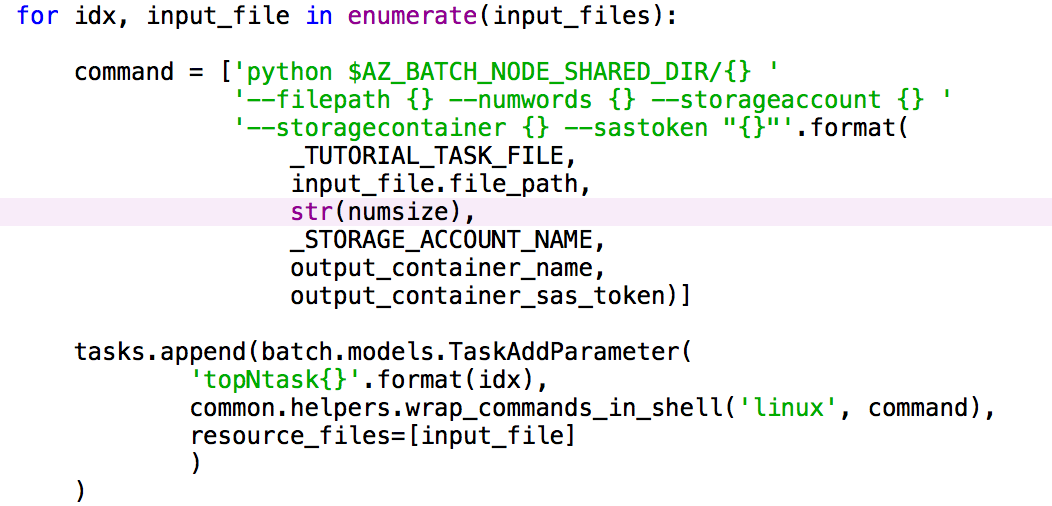
- クライアントコードのmain関数の始めにAzure Tableを作成 します。

- 区間を1億の小区間に分ける分割点を100個のファイルに分散して保存します。
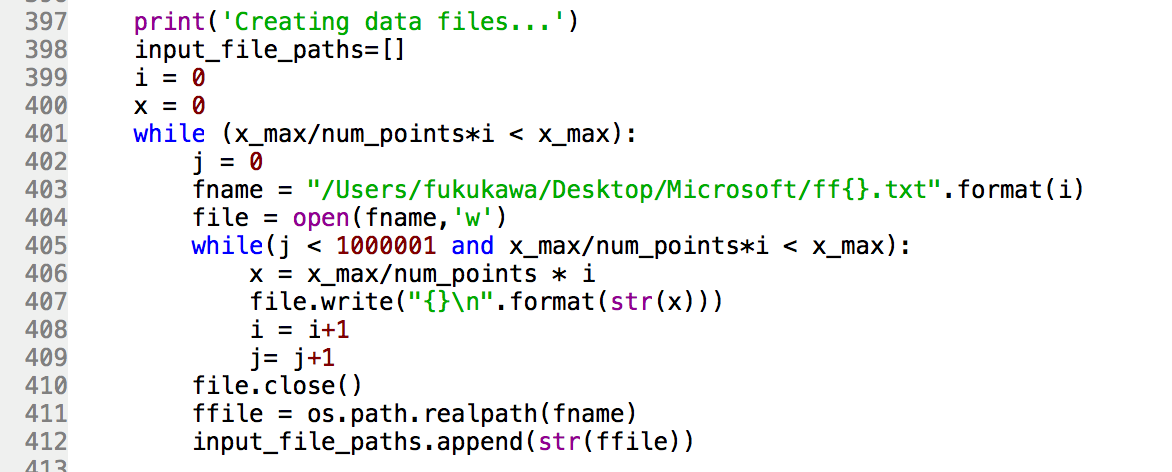
- タスク完了後に開始されるクライアントコードの位置に記録された部分和をAzure Tableから読み取って、 全て足して、リーマン和の結果を標準出力(STDOUT)で出力するようにします。このプログラムでは関係のないアウトプットファイルのダウンロード等のコードは消します。クライアントコードは以上です。
次はタスクコードの方に進みます。

- 必要な、argparse, datetime, os, math, とazure.storage.blobをインポートします。
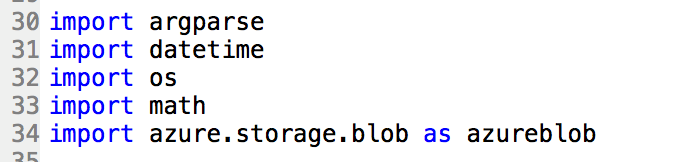
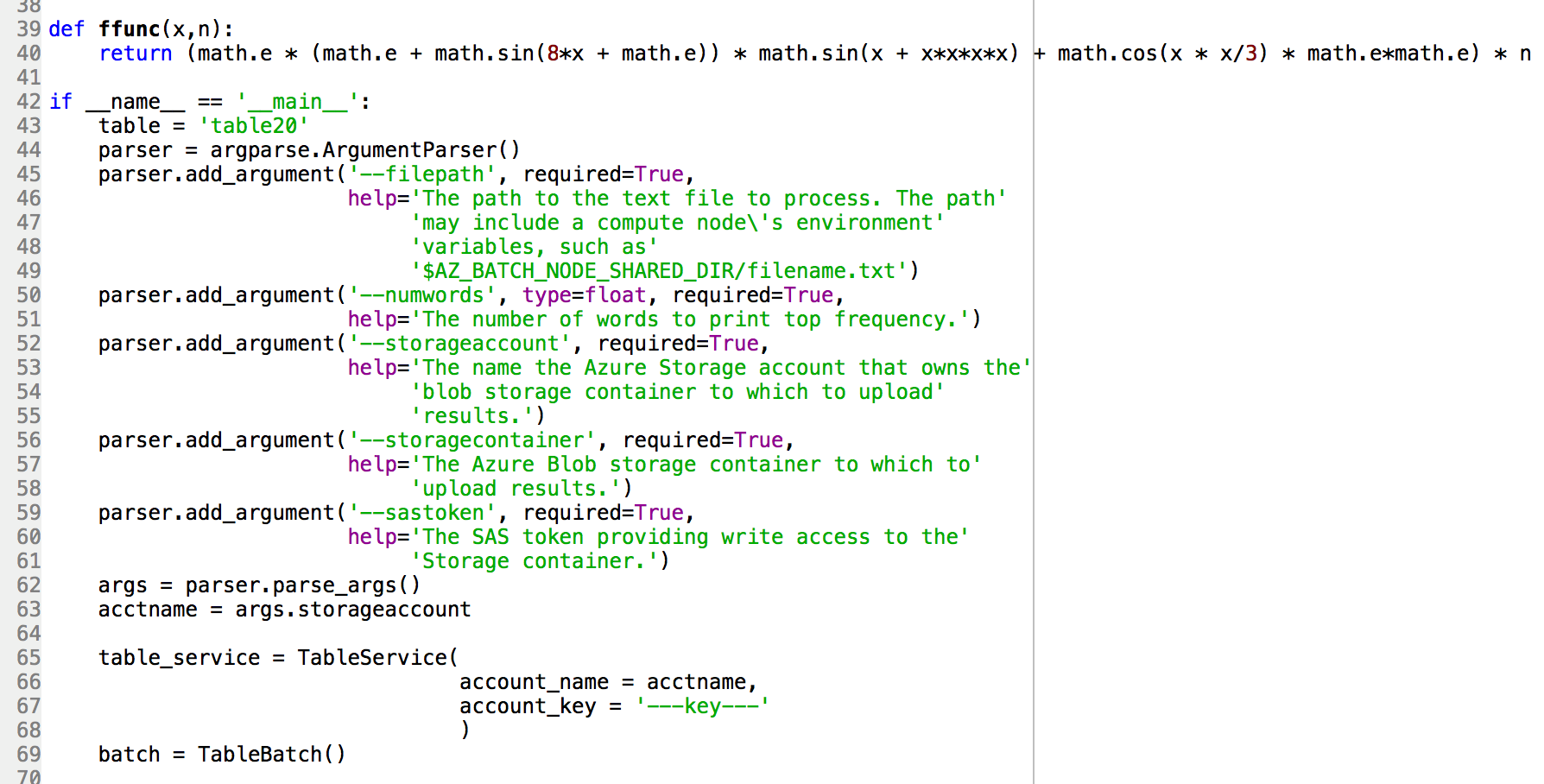
- 計算する数式をmainの外に関数として定義します。
- Azure Table の名前とストーレッジアカウントの名前とキーを入力します。
- パーサーの numwords引数のタイプをfloatにします。
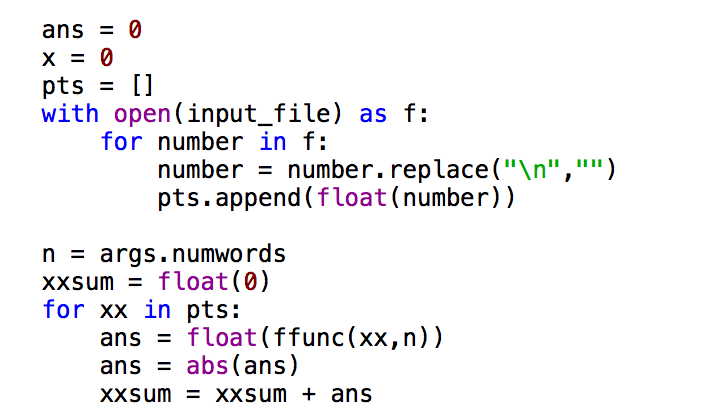
- インプットファイルから数字を読み取って扱いやすくするために配列にします。
- この配列の数字を数式の関数に通し、インプットファイルの部分和の合計を計算します。
- 合計した部分和をAzure Tableに入れました。Azure Table のRowKeyを特異のストリングにするため、日付、時間、と部分和を足して作ります。
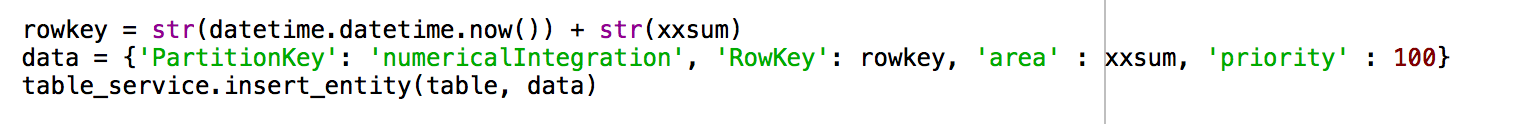
- アウトプットファイルのダウンロードに関するコードを消します。
以上です。コマンドラインでクライアントコードを実行して計算時間を記録します。